или „Защо всеки специалист по онлайн маркетинг трябва да бъде и статистик“.
Нека започна директно с основното твърдение в статията:
Интернет маркетингът в огромната си част не се базира на факти.
Ето, казах го, при това с удебелен наклонен шрифт, така че трябва да е вярно. Интернет маркетингът не се базира на данни и не се основава на факти толкова, колкото си мислите и, за съжаление, повечето специалисти не знаят това. Уви, това не е голословно твърдение. В следващите редове ще го докажа и ще демонстрирам как това пречи на работата на всеки, занимаващ се с онлайн маркетинг .
В маркетинга не се ли използват солидни данни?
Накратко – не. И това не е само моят опит през всичките тези години. Изследване на „CEB“ цитирано от Harvard Business Review, базирано на анкета сред около 800 специалисти по интернет маркетинг, работещи в компании от Fortune 1000, установява, че огромен брой маркетолози все още разчитат основно на интуицията си. И, за да станат нещата още по зле – малкото, които активно използват данни, в по-голямата си част го правят неправилно.

{kind=link}
{kind=link}
Ето две от основните заключения на изследването:
Повечето маркетолози разчитат твърде много на интуицията си – усреднено те използват данни само за 11% от всички решения, отнасящи се до клиентите. Когато биват запитани за данните, на чиято база взимат решения, свързани с работата си, се оказва, че повече от половината от информацията идва от предишен техен опит или от интуицията им за клиентите. Те поставят данните на последно място в списъка, като пред тях са: разговори с мениджъри и колеги, експертни съвети и еднократни разговори с клиенти.
Огромната част от маркетолозите имат трудности със статистиката – изследователите се опитват да измерят запознатостта на специалистите по онлайн маркетинг със статистиката с помощта на кратък тест от пет въпроса, с ниво на трудност от „начинаещ“ до „напреднал“. Почти половината (44%) се провалят, отговаряйки грешно на 4 или повече въпроса. Само 6% отговарят правилно и на петте. На този фон фактът, че едва 5% от тях притежават книга по статистика вероятно не изненадва никого.
„Маркетолозите не са по-различни от шамани“ – този извод определено трябва да привлече внимание през 21-ви век, нали? Очаквах такава новина да разтърси индустрията и мениджърските кръгове. За съжаление, сгреших – интересът към статията е незначителен. По-страшното е, че много от хората, коментиращи по подобни теми призовават за някакво „единение“ на интуицията и данните. Това може да означава само едно нещо – те нямат никакво концептуално разбиране за това какво е „факт“ и как се установява.
Наистина ли е толкова зле положението?
Да, а вероятно и по-зле, отколкото си мислите.
Опитайте се да си спомните кога за последно сте срещнали съвсем елементарното понятие „статистическа значимост“ (ниво на значимост) споменато в проучвание, изследване, публикация в блог или форум на тема интернет маркетинг (SEO, реклама в търсачки, оптимизация на конверсии и т.н.)? Колко инструменти за уеб анализи, табла за управление или спомагателни инструменти ви дават такава информация? А какво ще кажете за не по-малко важното понятие „статистическа мощ“ (мощност на критерия)? А за „Проблема на любопитния маркетолог“? „Проблем на множеството тестове“ извиква ли нещо в съзнанието ви?
Ако никога не сте чували тези термини, е добра идея преди да продължите да се хванете здраво за стола, тъй като тези концепции влияят на всички ваши процеси на взимане на решения, без значение дали се занимавате с SEO, платена реклама в търсачки, оптимизация на конверсиите или уеб анализи с някаква друга цел.
Преди да се гмурнем в дълбокото обаче, да си припомним някои по-елементарни и фундаментални неща.
Как придобиваме знания за света?

Методът, на който се базира всяко знание се нарича индукция. Наблюдаваме извадка от дадено явление чрез сетивата и ума си, и на база на тези наблюдения установяваме факти за цялата концепция, част от която е явлението. Елементарен пример: наблюдаваме множество обекти, които, след като се пуснат от определена височина над земята, падат по дадена траектория с дадена скорост и установяваме гравитацията.
От друга страна можем да наблюдаваме няколко пияни, високи, червенокоси мъже да грабят и убиват и погрешно да заключим, че всички червенокоси мъже грабят и убиват.
Как да се предпазим от подобни погрешни заключения?
Отговорът е: правилен дизайн на експериментите за проверка на хипотеза и правилна употреба на статистиката. Пример за правилен дизайн на експеримент би било да имаме произволност в извадката и да се опитаме да я направим представителна за цялото население. В горния пример това би означавало да включим произволно избрани червенокоси мъже. Това ще повиши вероятността да включим трезвени и ниски червенокоси мъже, правейки нашите заключения много по-реалистични. Ако сме по-напреднали, ще искаме да запазим пропорциите на важни характеристики на наблюдаваната извадка възможно най-близки до пропорциите им в цялото население.
Пример за добра употреба на статистика e да изчислим статистическата значимост на наблюдаваните данни спрямо това, което очакваме да видим.Нивото на значимост не премахва несигурността в нашите индукции, а ѝ дава количествена измеримост. Това ни позволява да имаме различни степени на сигурност, че наблюдаваните резултати не се дължат на случайност (като например наблюдението ни над червенокосите мъже). Имайки такава измеримост, можем да сравним ситуацията с игра на покер: колкото по-сигурни сме, че имаме по-добрата ръка, толкова по-склонни сме да заложим на нея.
Защо онлайн маркетинга трябва да бъде наука
Трябва да се разбере, че в маркетинга се опитваме да достигнем определени истини (обикновено за миналото, но и предсказващи бъдещето) и на тяхна база да направим препоръки или да извършим определени действия за подобряване на бизнес резултатите. Нещото, което повечето хора без научно или философско образование не разбират е, че в момента, в който се заговори за „истина“, веднага се навлиза в полето на науката, на рационалния емпиризъм, където научният метод е задължителният инструмент.
Речниковото определение за научният метод е „сбор от техники за изследване на различни обекти, придобиване на ново знание или коригиране и интегриране на предишно знание“. По-просто казано това към момента е единствения доказан подход, който ни позволява да различим реалните факти от игрите на нашите сетива и ум. Съществена част от този подход към обективната реалност са: добрата статистика – за установяване на емпирични факти и здравата логика – за да правим изводи и да свързваме тези факти. Примера с индукцията по-горе е научният метод в действие.
Ако не използваме научния метод, реално извършваме магически ритуали. Дори и да имаме най-добри намерения и да сме абсолютно непредубедени, ако ни липсва добро разбиране за статистиката често ще се окажем в ситуация да преследваме статистически „призраци“ и да вървим с километри към статистически „миражи“. Казано иначе, има съвсем реална възможност да похарчим много пари и да вложим много усилия, мислейки си, че постигаме резултати, а в действителност да стоим на едно място.
В следващите абзаци ще разгледам 3 основни концепции от статистиката, които всеки специалист по интернет маркетинг трябва да познава отлично за да може да избягва горната ситуация. Това са: Статистическа значимост, Статистическа мощ и Проблемът на множеството сравнения.
Статистическа Значимост
Статистическата значимост (срещана още като „ниво на значимост“) е важна концепция в тестването на нулева хипотеза – инструментът с главно „И“ за анализ на данни и извличането на информация от тях. Най-често в онлайн маркетинга искаме да тестваме дали един или повече варианти се представят по-добре от досегашния (напр. рекламни текстове, ключови думи, целеви страници и т.н.). Хипотезата по подразбиране е, че това, което наблюдаваме няма да предизвика подобрение. Ето защо при всеки един тест или наблюдение ние търсим доказателства, че можем да отхвърлим хипотезата по подразбиране.
Когато видим подобрение в даден параметър, който измерваме (CTR, CPC, ниво на конверсия, степен на отпадане и др.) не можем просто да заявим, че вариантът е по-добър. Това се дължи на факта, че наблюденията ни винаги са върху малка част от хората, които ни интересуват. Правенето на извод за всички хора на базата на само част от тях неизбежно води до грешки. Ето защо трябва да имаме идея за възможността данните, които виждаме, да са грешни.
Having a certain level of statistical significance expresses the likelihood that the difference we observe (or a bigger difference) would not be observed if there was no actual difference. To take a textbook example – having a statistical significant result at the 95% level means that there is only a 1 in 20 chance that improvement as big, or bigger than the observed, could have been encountered by chance alone.
Тук се намесва статистическата значимост. Достигането на дадено ниво на статистическа значимост изразява вероятността разлика, равна или по-голяма на тази, която наблюдаваме, да не бъде наблюдавана ако няма разлика. Елементарен пример: ако имаме статистически значим резултат с ниво 95% означава, че има само 1 към 19 шанс разлика равна или по-голяма от наблюдаваната да бъде регистрирана по чиста случайност.
Колкото по-голяма е наблюдаваната разлика, толкова по-малко данни ни трябват, за да потвърдим по статистически значим начин, че има подобрение. Колкото повече данни имаме, толкова по-лесно е да засечем по статистически значим начин дори малки разлики в представянето.
Ето и по-конкретна демонстрация на концепцията:

Дискутиране на „статистическа значимост“ в индустрията
Исках да разбера колко внимание се обръща в индустрията на тази важна концепция, затова се поразрових.
Avinash Kaushik е един от първите, който е писал за важността на статистическата значимост в уеб анализите през 2006-та година. LunaMetrics, наложен източник за ноу-хау в уеб анализите, споменава нивото на значимост едва няколко пъти и има една кратка статия, посветена на темата. Дори в блога на Google Analytics има само три споменавания на термина през всичките години, откакто съществува. Техния водещ евангелист Justin Cutroni споменава термина само веднъж в своя блог. KISSMetrics, иноватори в уеб анализите, обявиха скоро, че вграждат нива на значимост в своите отчети.
В SEO сферата SearchEngineWatch, сериозен източник за SEO и PPC публикации за повече от 7 години има само 20 статии, в които се споменава статистическата значимост. В SearchEngineLand пък терминът се среща в едва няколко статии, най-добрата от които е от 2010-та.
Най-добро покритие на темата има при фирмите за оптимизация на конверсиите: VisualWebsiteOptimizer, Optimizely, а също и Google Website Optimizer винаги са имали изчисляване на нива на значимост в софтуера си и са публикували и статии за това.
Това в общи линии е всичко, което може да се намери по темата сред публикациите на лидерите в индустрията – спорадични споменавания, без особено задълбочаване, с малки изключения. Защо това да е лошо и до какво води пренебрегването на статистическата значимост? Да видим най-често допусканите грешки по отношение на нивата на значимост.
Често срещани грешки относно статистическата значимост
Първата и най-банална грешка е въобще да не се провери статистическата значимост на данните. Повечето хора се провалят още на тази стъпка. Според източници от индустрията специалистите масово не изчакват достигането на добри нива на значимост дори при контролирани A/B тестове. Други ситуации, в които се пропуска да се провери статистическата значимост са при анализ на: представянето на рекламни криейтиви, CTR и нива на конверсия на ключови думи, конверсии при CPC кампании, SEO и други. Това ни оставя без какъвто и да е обективен измерител за данните, с които работим.
За съжаление такива случаи се срещат и в литературата, а и в сериозни блогове за онлайн маркетинг. Този пример е от скорошна публикация в блога на VisualWebsiteOptimizer. Примерът е взаимстван от бестселър по въпросите за тестването:
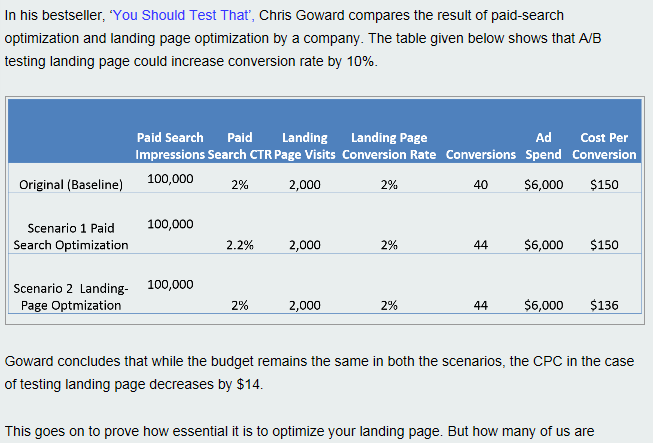
Виждате ли проблемите?
За начало, числата в таблицата не кореспондират на процентните стойности. Но дори и да оставим това настрана, разликите в степените на конверсия между сценариите и базата са далеч от каквито и да е приемливи нива на значимост! Между 2% и 2.2% не може да бъде направена никаква разлика от статистическа гледна точка. Това не е малка грешка, а огромен провал в опит да се ползват най-елементарни данни.
Да не се измерват нивата на значимост означава, че има голяма вероятност да инвестирате ресурси в сриването на собствения си бизнес, без дори да разберете това! От бизнес перспектива на нивото на значимост може да се гледа като на измерител на риска, който съпътства взимането на дадено решение. Колкото по-високо е нивото на значимост, толкова по-малък е рискът. Съответно колкото е по-голям е очакваният ефект от решението, толкова повече трябва да разчитате на статистиката (и към толкова по-голямо ниво на значимост ще трябва да се стремите).
Втората често срещана грешка е да се бърка статистическата значимост с практическата значимост на резултатите (големината на ефекта). Тя се допуска от хората, които правят изчисления за нивата на значимост на резултатите си и приемат статистическата значимост за практическа такава. Статистическата значимост ни казва колко сигурни можем да сме, че има разлика между два параметъра, но не ни казва нищо за това колко голяма е разликата! Статистически значим резултат може да има реално подобрение от 0.01%, дори ако нашия експеримент показва 50% подобрение.
Ето един бърз пример:

Нивото на постигната значимост е много високо, но забележете сините числа в колонката „% Change“. Те ни казват, че въпреки, че отчетеното от теста подобрение е 60%, реалното подобрение, което можем да предскажем с 95% увереност, с тези данни, е между 15% и 105%, като всички стойности са еднакво вероятни!
Много известен случай за такава грешка е изключително популярното и цитирано проучване на SEOMoz за факторите за класиране в търсачките. Изследването твърди, че са достигнати значими резултати, които показват как различните SEO фактори корелират с класирането в резултатите на търсачките. Те обаче пропускат да ни информират, че техните статистически значими резултати всъщност имат нищожна практическа значимост и съответно не подкрепят твърденията им за сериозна корелация на различните сигнали. В това изследване няма откритие, тъй като нивото на корелация е нищожно! Подробна дискусия по темата може да бъде намерена на блога на Dr. Garcia тук и тук, а също и на блога на Sean Golliher за компютърни науки и изкуствен интелект тук.
Този тип грешни заключения водят до преувеличени очаквания към резултатите и съответно – за потенциалните печалби. Анализ на приходите и разходите, който почива на такава фундаментална грешка може да има ужасни последици.
Третия тип грешка е да се интерпретират резултатите с ниски нива на значимост като подкрепящи тезата за липса на разлика/ефект. В този момент е редно да поговорим за
Мощ на Статистически Тест
Статистическата мощ зависи от размер на извадката (броя посещения, импресии и т.н.), от която си вадим заключенията и от минималното подобрение, което има смисъл за нас. От една страна мощта на теста определя вероятността да отчетем коректно ефект с практическа значимост. Колкото е по-голяма тя, толкова по-голям е шансът за това. От друга страна, мощта има и огромен ефект върху изчисленията на статистическата значимост, като може да се стигне дотам, че да ги направи абсолютно безполезни.
Има два начина да се сгреши по отношение на статистическата мощ: да се проведе експеримент с твърде малка или твърде голяма мощ. Един тест има твърде малка мощ, ако броя наблюдения е твърде малък, за да засечем наблюдаваното подобрение с желаното от нас ниво на значимост. Тест с твърде голяма мощ пък има излишно голям брой наблюдения спрямо търсените резултати.
Грешка със статистическата мощ #1
Първото, което може да се случи, ако мощта на теста е недостатъчна, е възможността да не успеем да отчетем реално съществуваща, практически значима разлика. Използвайки такъв тест ще заключим, че промените ни не са довели до ефект, когато в действителност такъв има. Тази често срещана грешка води до пропиляване на бюджети за тестове, които така и не получават достатъчно трафик, за да се види ефекта от различните варианти. Какъв е смисълът да правим тест след тест, ако боравим с недостатъчно данни, за да засечем желаното подобрение?
Печален е резултатът от неправилната употреба на статистическата мощ през 70-те години в САЩ, когато на шофьорите е позволено да правят десен завой на червен светофар. Това се е случило след серия от пилотни тестове, при които не са забелязани увеличения в броя произшествията. Проблемът е, че тези тестове са били с твърде малки извадки, за да се засече какъвто и да е значим ефект. По-късно изследвания с достатъчно големи извадки демонстрират, че това решение е коствало много животи, да не говорим за травмите и имуществените щети.
Грешка със статистическата мощ #2
Другият проблем, свързан с недостатъчната мощ, се появява когато проверяваме междинни резултати от теста, преди неговото планирано приключване. Тогава е възможно видим статистически значими резултати (и често практически значими), когато в действителност такива няма. Проверката на нивото на значимост само след като теста е събрал необходимите данни ви предпазва напълно от тази грешка.
Ако не го направите и спрете даден тест предварително (преди достигане на определения брой импресии/посещения и т.н.), това увеличава многократно вероятността за фалшиви нива на значимост. Това най-често се случва при непрекъснато следене данните и спиране при достигане на желаното ниво на значимост. Правейки това, можем да достигнем и до 100% вероятност да регистрираме статистически значим резултат, правейки всякакви изчисления на значимост безполезни. Ето защо избързването и вземането на решение да се спре теста веднага, щом се регистрира статистически значим резултат е непродуктивно.
Ето реален пример от първите опити на CrazyEgg с А/Б тестовете:
„Когато започнах да правя А/Б тестове върху сайта на Crazy Egg преди три години, направихме седем теста за пет месеца. Софтуера за А/Б тестове показваше, че сме подобрили конверсиите си с 41%. Не виждахме, обаче, никакво повишаване в приходите си. Защо? Защото не пускахме тестовете да вървят достатъчно дълго…“
Четейки по-нататък в блог поста на Neil Patel става пределно ясно, че проблема, който е изпитвал се е дължал именно на стратегията „спиране, базирано на значимост“, описана по-горе (неговите обяснения за избягването на проблема не е коректно). Ако допуснем горната грешка, можем да правим тест след тест и да си мислим, че имаме голям успех, а в същото време да не постигаме нищо, или да вредим. Вероятно много от нас са били в подобна ситуация – действаме според успешен, статистически значим тест, а след няколко седмици или месеци откриваме, че ефектът върху бизнес резултатите далеч не е този, който сме очаквали.
Както Проф. Allen Downey казва в тази отлична публикация: „Повтарянето на един тест много пъти е добра практика, ако дългосрочните ви амбиции са да грешите 100% от времето.“
Ето илюстрация на втората грешка при употребата на статистическа мощ:
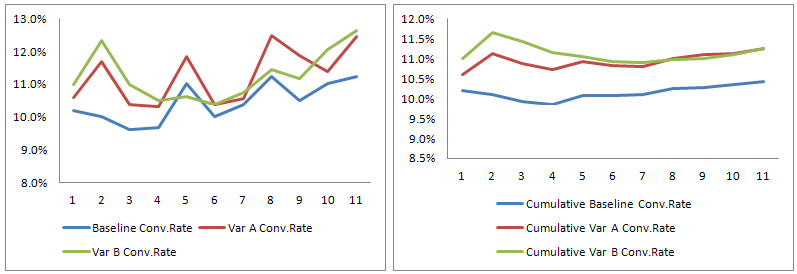
Ако имаме данни за конверсиите от първите 16 дни като посочените по-горе и имаме 95.9% статистическа значимост за разликата между базата и вариант Б в края на 16-тия ден, следва ли да се обяви вариант Б за успешен и да се спре теста?
Ето пълните данни от експеримента – 61 дни. Оранжевата линия е нивото на значимост (дясна скала) за вариант Б спрямо базата. Двете сиви хоризонтални линии представляват нива на значимост – 90% и 95%.
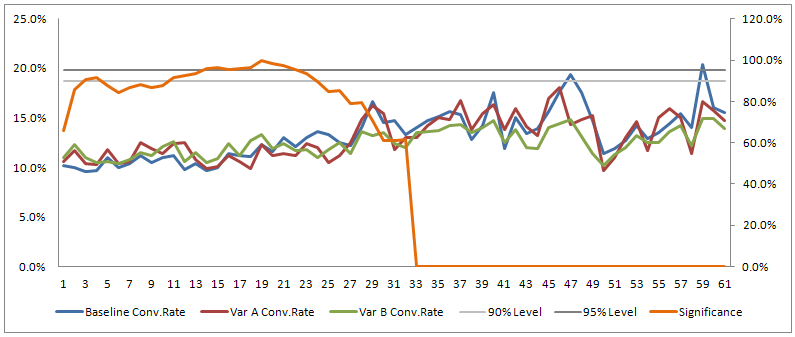
Търсейки значимост от 95% и действайки щом я достигнем, без да изчакаме да имате съответната мощ за засичане на наблюдаваната разлика, то погрешно ще изберем вариант Б, ако вземем решение между 16-тия и 22-рия ден. Ако целта ни е ниво на значимост 90%, ще имаме фалшиви положителни резултати още на 3-тия и 4-тия ден, а също и между 11-тия и 23-тия ден.
Ето как в този случай нашия експеримент не успява да посочи по-добър вариант, тъй като всички те се връщат към нормата (получавате бонус точки, ако сте забелязали, че първите две графики не започват от нулево ниво). Ранното определяне на „победител“ базирано само на статистическа значимост щеше да бъде още по-голяма грешка, ако резултатите на вариант Б след 16-тия ден бяха по-лоши от показаните.
Този пример демонстрира защо е важно да изчакваме докато тестът получи достатъчно сила. Тъй като проблемът тук е „надничането“ в данните и реално е извършване на тест за значимост всеки един ден, това е и частен случай на „Проблемът с многото сравнения“ , който ще дискутирам в детайл по-долу.
За съжаление такива грешки бяха и продължават да се окуражават от някои инструменти за A/Б тестове, така че ще завърша частта за избирателното спиране този цитат от Evan Miller:
Ако пишете софтуер за A/B експерименти: Не показвайте нива на значимост преди да приключи експеримента и престанете да ги използвате, за да решавате дали даден експеримент трябва да спре или да продължи. Вместо да показвате нива на значимост за текущи експерименти, показвайте колко голям ефект може да бъде засечен с текущия размер на извадката. Колкото и болезнено да звучи, може дори да се наложи да не показвате “текущо изчисление” за големината на наблюдавания ефект, докато експеримента не приключи. Ако тази информация се използва за спиране на експерименти, тогава показваните от вас нива на значимост не стават за нищо.
Грешка със статистическата мощ #3
Последната грешка по отношение на мощта е да се направи изследване с твърде голяма мощ. В този случай най-вероятно ще бъдат пропилени пари и други ресурси, тъй като тестването ще продължи след като вече имаме резултати със сигурността, която ни удовлетворява. Повече по въпроса вероятно ще пиша в последваща публикация.
Имайки всичко това предвид, очаквах статистическата мощ да бъде дискутирана поне колкото статистическата значимост. Реално, обаче, броят споменавания на статистическата мощ клонят към нула в повечето известни блогове и сайтове за интернет маркетинг. Evan Miller е от първите, които предизвикват някакво внимание към проблема в рамките на оптимизацията за конверсии със своята публикация от 2010-та година How Not to run an A/B test.
VisualWebsiteOptimizer са другите, които пишат по въпроса. Имат немалко споменавания в рамките на техния сайт и блог, като тази публикация заслужава специално внимание. От друга страна обаче, на сайта си имат огромен брой „case studies“, само половината от които споменават статистическата значимост на резултатите, а в нито едно не се споменава статистическата мощ.
Тази публикация на Noah от 7signals – determining sample size for A/B tests е друг пример за добра информация, който успях да намеря. От Optimizely споменават статистическата мощ на забутано място в рамките на дълга страница за „chance to beat original“, част от тяхната помощна информация.
KISSMetrics, както споменах по-горе, скоро започнаха да предоставят изчисления на нивото на значимост в своя инструмент, което само по себе си е сериозна стъпка напред за уеб анализите. Те обаче не споменават „статистическа мощ“ при пускането на тази функционалност. И това се случва само дни след като публикуваха тази статия на същата тема (за момента не съм съгласен с някои от заключенията в нея). KISSMetrics подхващат темата, вдъхновени от една добра публикация на Qubit – Most winning A/B test are illusory (pdf) , която се появи по-рано тази година.
Забележка относно използването на безплатни калкулатори за размер на извадката. Внимавайте за следните особености, когато ги използвате:
На първо място, повечето от тях изчисляват размер на извадката за двустранна хипотеза. По този начин те препоръчват по-голям от необходимото размер на извадката по отношение на масовия случай в онлайн маркетинга. Обикновено ни интересува само дали и колко голямо е подобрението, но не и точността на резултатите, които се представят по-зле от контролната група. Ако се ръководите от техните изчисления, ще харчите излишно бюджети за генериране на трафик или импресии.
Второ, някои от тях калкулират само за базов процент на конверсия 50% , което е безполезно в онлайн маркетинга, където се работи с най-различни базови проценти. Трето, други (например безплатния калкулатор на CardinalPath) изчисляват при фиксирана статистическа мощ от 50%. Това означава, че шанса да се пропусне статистически значим резултат с желаната степен на подобрение е 1 към 2.
С калкулатора в Analytics-Toolkit.com сме се постарали да отговорим на тези проблеми.
Продължаваме с най-трудния за разбиране проблем…
Проблемът с многото сравнения
Проблемът с многото сравнения се появява всеки път, когато имаме резултати от експеримент с повече от един вариант, сравнен спрямо базата. Просто казано: колкото повече тестваме за дадено нещо, толкова по-вероятно е да регистрираме положителен резултат, без да имаме такъв. Колкото повече вариации създаваме, толкова по-вероятно е някои от тях да покажат статистически значими резултати при положение, че реално такива няма. Това е една от причините маркетолозите, които тестват с повече варианти, погрешно да докладват много по-добри резултати от нормалните.
Например, имаме базова степен на конверсия за ключови думи в AdWords и се опитваме да идентифицираме една или повече ключови думи, които се представят по-добре от базата по статистически значим начин (и с достатъчно мощ). За да направим това, решаваме, че искаме ниво на значимост от 95% и започваме да сравняваме степените на конверсия за всяка от 13-те ни ключови думи с базата, търсейки такива, които ще покажат подобрение при това ниво на значимост.
Ако има само една ключова дума и искаме да проверим само нея спрямо базата, няма да има проблем. Ако има 13 ключови думи и сравним всяка от тях с базата, нещата се променят. Ако открием един значим резултат при ниво 95% и решим да насочим по-голяма част от бюджета към тази ключова дума, това ще бъде грешка.
Да видим защо. Изборът на ниво на значимост от 95% означава, че сме склонни да приемем шанс 1 към 20, че наблюдаваното подобрение в степента на конверсия се дължи на случайност, а не на реален ефект. Сравнението на всяка една от тези 13 ключови думи с базата ще доведе до това, че ще има около 50% шанс едно от тези сравнения да бъде статистически значимо при положение, че не е. Това означава, че ще има грешен положителен резултат при сравнение на 13-те ключови думи всеки втори път, когато го правим.
В крайна сметка нивото на значимост от 95%, което ще отчетем за тази ключова дума, всъщност няма да е 95%, а много по-ниско. Желанието да се избегнат фалшивите положителни резултати е нещо, което предполага корекция на нивата на значимост при множество сравнения. Можем да направим това на база броя експерименти или варианти, и на значимостта на резултатите им.
Има един чудесен комикс в xckd по тази тема.
Според мен за практически приложения в сферата на интернет маркетинга методът за корекция False Discovery Rate е най-подходящият. С него се коригират нивата на значимост на всеки вариант/група с цел да се изчисли реалната значимост, когато имаме сценарий с множество сравнения.
Ето един елементарен пример със с 3 варианта (увеличаването на броя варианти увеличава проблема):
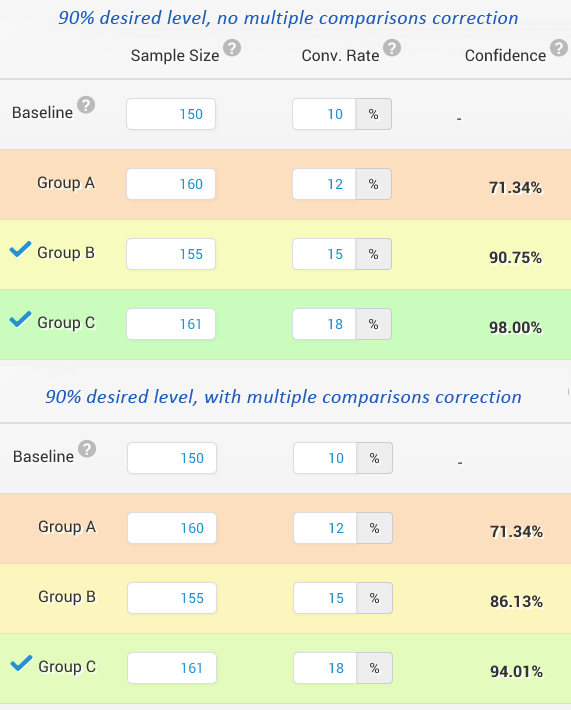
Разликите в нивата на значимост с и без корекция са очевидни. Получавате бонус, ако сте забелязали, че горните изчисления за значимост са с недостатъчна мощ на теста 😉
Реално всички инструменти, показващи статистическа значимост, които съм разгледал, НЕ коригират нивата на значимост, когато имаме ситуация с множество сравнения
Дори в иначе добрата публикация на Qubit, която споменах по-горе, авторите не успяват да обяснят проблема с множеството тестове коректно. В нея се споменава, че донякъде е проблем, но не се споменават методи за корекция на нивата на значимост. Вместо това се препоръчва да се експериментира с минимален брой варианти и да се придържаме към онези, от които се очаква значителен ефект.
Тестването на много варианти е напълно защитим подход, когато се прави както трябва (със сигурност не препоръчвам произволното правене на експерименти). Също така, ако при оптимизация на конверсиите обикновено можете да ограничите броя варианти, когато се правят изследвания на различни източници на трафик и тяхното представяне, често е невъзможно да се ограничи броя варианти или групи, които се анализират. Фундаментална грешка е работата само с част от наличните данни по даден въпрос, избрана по непроизволен начин.
Повечето калкулатори за статистическа значимост са безполезни или грешат
Имайки предвид горния проблем смятам, че всички безплатни онлайн калкулатори на нива на значимост, които са ми известни, са или практически безполезни, или с фундаментални проблеми. Повечето от тях изчисляват статистическа значимост само за един вариант спрямо базата. Това ги прави неподходящи за реална употреба, тъй като най-често ни се налага да сравняваме няколко рекламни текста, целеви страници, източници на трафик, ключови думи и др., когато търсим начини да подобрим тяхното представяне. Както обясних по-горе, използването на такъв калкулатор и правенето на множество сравнения по двойки, означава допускането на много по-голяма несигурност от тази, която той ни показва.
Други калкулатори позволяват сравнението на база с няколко варианта. Това е по-добре, но повечето дори не се опитват да коригират резултатите, отчитайки проблема на многото сравнения. Това може да има видими ефекти дори само при три варианта, както демонстрирам по-горе. Известен ми е един опит да се направи добър калкулатор за статистическа значимост, който работи с множество варианти и коригира за грешките, причинени от многото сравнения. Той обаче използва метода за корекция на Dunnett, който е излишно стриктен, когато се отнася за практически приложения.
Към момента единственият известен ми калкулатор, поддържащ множество сравнения и коригиращ за грешки по практичен начин, е изработеният от мен statistical significance calculator. Него използвам и за примера по-горе.
OK! Но какво да ПРАВЯ с всичко това?
Разбирам, че вероятно е било трудно на повечето от вас да стигнат до тази част от публикацията, но ако сте успели – поздравления, вие сте един корав специалист по маркетинг!
Ето и какво мисля, че можете да направите, ако искате да подобрите качеството на работата си чрез истински подход, базиран на данни:
#1 Научете се как се прави експеримент и как се тества хипотеза. Приложете наученото в ежедневните си задачи.
#2 Учете статистика и прилагайте знанието в ежедневните си задачи. Неща за избягване: Баезианския подход към статистиката (нищо против правилото на Баез).
#3 Настоявайте за по-добри статистики от компаниите, правещи инструменти за онлайн маркетинг. Свържете се с тях и им кажете, че ви е грижа за добрите данни и за добрите решения. Те ще ви чуят.
#4 Образовайте своя ръководител, клиентите си и всички останали, които имат полза от работата ви за вашата новооткрита суперсила и за това как тя може да работи за тях.
За случая е подходящ този страхотен цитат на Evan Miller: „Да можеш да работиш със статистика е като да имаш тайна суперсила. Там, където повечето хора виждат средни стойности, ти виждаш интервали на сигурност. Когато някой ти каже “7 е по-голямо от 5,” ти заявяваш, че всъщност са едно и също. В какафония от звуци чуваш вик за помощ.“
В блога на Analytics-Toolkit.com ще се опитаме да помогнем по отношение на точки #1, #2 и най-вероятно индиректно за точка #4, като публикуваме още статии като тази за парадокса на Симпсън в онлайн маркетинга. Те ще покрият някои от концепциите в настоящата статия по-пълно, а ще има и практични съвети за това как правилно да проведем даден тест, как да анализираме данни от Google Analytics или Google Adwords и изобщо всичко, което има връзка със статистиката в онлайн маркетинга. Първите ми публикации ще разглеждат въпроса как да изберем подходящо ниво на значимост и мощ на теста, така че е добра идея да ни следите.
Послеслов
Започнах да пиша тази статия с голямо вълнение, защото имам истинска страст към добрия маркетинг за добри продукти и услуги и искам да постигам реални резултати в това, което правя.
Целта на тази публикация е да предизвика внимание към проблеми, които считам за критично важни за цялата онлайн маркетинг индустрия и за всеки, разчитащ на нашата експертиза. Смятам, че успешно доказах съществуването на тези проблеми, колко широко разпространени и дълбоко проникващи са и колко опасен е ефектът от тяхното пренебрегване. Надявам се вече е ясно защо считам, че всеки специалист по онлайн маркетинг трябва да започне да прилага по-научен подход в работата си.
Бих искал да завърша с една мисъл на Evan Miller:
Една гледна точка към историята на бизнеса през 20-ти век е като към серия от трансформации, при които индустриите, на които „математиката не им трябва“ изведнъж се оказват в критична зависимост от нея. Статистическия контрол на качеството преоткрива фабричното производство; икономиката на земеделието преобразява земеделското производство; дисперсионния анализ революционира химическата и фармацевтичната индустрии; линейното програмиране променя лицето на управлението на доставките и логистиката; уравнението на Black-Scholes създава индустрия от нищото. Още по-скорошно “Moneyball” техниките превзеха спортния мениджмънт…
Ако искате да помогнете да повишим вниманието към тези проблеми и така превърнем интернет маркетинга в по-добра и базирана на факти дисциплина, популяризирайте идеите в тази статия по какъвто начин и в каквато форма смятате за удобни. Приключвам с кратък апел към всички, правещи инструменти за онлайн маркетинг – моля, опитайте се да улесните вашите потребители във взимането на решения, базирани на факти. Те без съмнение ще са ви благодарни, тъй като който има по-точните факти има по-голям шанс да успее.
Георги Георгиев
Основател на Analytics-Toolkit.com
Full disclosure: Не съм дипломиран/сертифициран статистик. Статията съдържа сравнително свободна употреба на статистически термини, особено що се отнася до „вероятност“, с цел да направи материала по-достъпен за масовата аудитория.
Етикети: маркетинг, мощност на критерия, ниво на значимост, проверка на хипотеза, статистика, статистическа значимост, уеб анализи
Това със сигурност е най-добрата статия, която съм чел някога на български по темата за електронния маркетинг. Да не говорим, че е и една от най-добрите като цяло, които съм чел напоследък.
Основната част от разлгеданите проблеми са ми вече познати, но към другите читатели мога да препоръчам горещо: четете и попивайте като гъби, разгледайте и външните препрадки. Което не ви е ясно, Google is your friend.
Подобна информация е не просто ИЗКЛЮЧИТЕЛНО трудна за намиране, но и невероятно ценна. Като човек, който е трябвало да си вади повечето от тези изводи сам (с учебника по статистика от УНСС…ох!), и редовно чете публикации на топ автори, мога да кажа само едно: Шапка ви свалям, не съм очаквал подобна статия в български блог.
Използваната терминология може и да е трудна за начинаещите, но с повечко усилия ще стане. Единствена препоръка към автора е да не се притеснява да използва чуждици, където е нужно. Някои термини просто не звучат добре на български 🙂
Ще прегледам статията отново утре и се надявам да се заформи добра дискусия, било то от 5 човека 🙂
Браво!
Здравейте Йоан,
Благодаря за хубавите думи, наистина статията е резултат на много четене и мислене 🙂 И да, на български подобна информация почти няма, но реално и на английски също е много трудна за намиране. Пълно е с дезинформация и с неправилно работещи инструменти, което е още по-зле. Затова и оригинала ми е на английски – http://blog.analytics-toolkit.com/2014/why-every-internet-marketer-should-be-a-statistician/, но след това реших, че ще я преведа и на български.
Ако ми кажеш и кои термини според теб не звучат добре на български, мога да помисля за алтернативи (старал съм се да ги направя по термините в учебниците по статистика, но за някои термини не видях писано нищо на БГ).
Поздрави,
Георги
Определено интересен поглед не мога да отрека, макар да има 1-2 неща, които можеше да са още по подробни 🙂
Например? И имай предвид, че това е статия, която по-скоро поставя начални въпроси, а не трактат, който има за цел да изчерпи материята 🙂
Здравейте.
Повече от чудесна статия от към съдържание. За съжаление малко хора в страната ни ( маркетолози, маркетьори, консултанти и т.н ) биха задълбали в такава дълбочина. И въпреки, че не е пряко по-темата – ако оправите часта с по достъпно ( дизайн, архитектура, топография и т.н ) представяне на информацията, с такива материали ще избиете родната конкуренция.
Адмирации за материала !
P.S. Искам да го споделя………….но къде са бутоните 😛
Надявам се повече хора да задълбаят, тъй като материята не е чак толкова сложна, ако се отдели малко време, а резултатите няма да закъснеят.
Бутоните са на разположение 🙂
Дано родната кошница от професионалисти в областа се увеличи драстично. Да стискаме палци и да се надяваме.
Поздрави !