Парадоксът на Симпсън е интересен за всеки, който се занимава с анализ на данни, включително специалисти по уеб анализи в интернет маркетинга. Независимо в каква сфера работите – оптимизация на конверсиите, оптимизация за търсачки, управление на AdWords кампании и др., парадоксът на Сипмсън може да ви даде храна за размисъл.
Той има връзка с правилния дизайн на експеримента, когато става дума за контролиран тест, и е изключително важен, когато изследваме вече събрани данни (в Google AdWords, Google Analytics и т.н.). Той е екстремен пример за това до какво може да доведе липсата на смислена сегментация. „Сегментирайте, сегментирайте, сегментирайте!“ е това, на което ни учи този парадокс.
Парадоксът на Симпсън – Пример
Нека видим практически пример: сравняваме степените на конверсия за Целева страница А и Целева Страница Б в рамките на няколко седмици. Ето данните:

Гледайки средните стойности изглежда, че Б побеждава А с добро ниво на значимост и в тест с достатъчно мощ. Изглежда сигурно, че имаме победител, нали? Само че, ако сегментираме данните по източник на трафик виждаме, че страница А се представя по-добре от страница Б са всеки отделен източник на трафик!
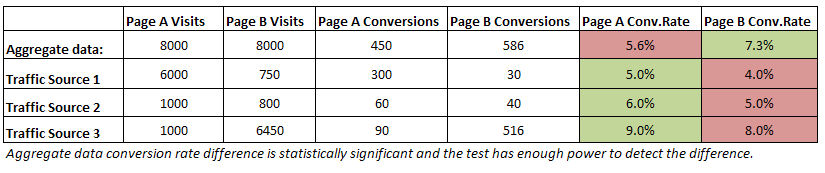
Как е възможно това?
Този странен ефект е причинен от претеглените средни стойности. В случая обема на трафик от всеки източник се явява „confounding variable“ (ако някой статистик знае термина на български, ще го напиша) или на жаргон „скрита лимонка“. Трафикът е разпределен неравно по двойките „източник на трафик/целева страница“ и в действителност заради това наблюдаваме тези резултати. Подобен пропуск може да доведе до това да сравняваме несравними неща.
Какво да правим в такъв случай, кой вариант на целева страница да изберем?
За начало трябва да се опитаме изобщо да не попадаме в подобна ситуация чрез използването на силно произволен тест (properly randomized). Друга, по-добра опция е да ползваме stratified sampling, но доколкото ми е известно повечето инструменти не поддържат такива опции, така че това може да не е осъществимо. Невъзможно ще бъде да коригираме това и при наблюдение на вече събрани данни, върху които нямаме контрол, например органичен трафик от търсачки.
Ако така или иначе вече сме в подобна ситуация, решението дали да действаме според средните данни или според данните по сегменти следва да се базира не толкова на числата, колкото на смисъла зад тях.
Моето разбиране за конкретния пример е, че трябва да се въздържим от вземане на решение с данните в таблицата. Бих препоръчал да разглеждане на всяка двойка „източник на трафик/целева страница“ от качествена гледна точка. Според това какъв е характерът на всеки източник на трафик (еднократен, сезонен, постоянен) може да се достигне до различно решение. Например можем да решим да запазим и двете целеви страници, но за различни източници на трафик.
За да направим това на база факти, трябва да се третира всяка двойка „източник на трафик/целева страница“ като отделен вариант и да се извършат допълнителни тестове докато получим добри нива на значимост при добра статистическа мощ (в текущите данни те не са налични).
Заключение
Задължително сегментирайте данните си по различни величини. В случай, че имате контрол върху сегментирането – например в контролиран тест за оптимизация на конверсиите, се опитайте да разпределите трафика произволно или ползвайте стратифицирано сегментиране. В случай, че просто анализирате данни в AdWords или Analytics, сегментирайте задълбочено, преди да достигнете до решение за действие.